Now I can use the drag & drop and produce RSS son, remains to be assembled with two prototype, scriptaculous and a little DOM to the interpretation of the RSS file.

processing on the server or the client?
Recovery and Interpret RSS files can be done either on the server, either from the desktop. The solution outlined here is based on processing at the client. This helps avoid overloading the server, but causes strong constraints related to AJAX. Indeed, AJAX can not retrieve files outside the domain of the calling page (except for Microsoft Internet Explorer). Surely I would present later a method to overcome this problem but this is beyond the scope of this presentation.
For the occasion I made available three RSS feeds, since the test database , from views as described in the previous chapter. The blog feed is based on data recorded in the test database, not data BlogSpot, but again I return to this subject in a future article. Set
RSS feeds to get
Before displaying the RSS feeds you will have to store the list of URLs of RSS files to display. For that I rely on a Notes form similar to that shown during the presentation of the Drag & Drop
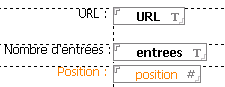
I need three fields:
- The URL of the RSS feed: a free text field
- Number entry to present: a field number or free text
- position of the stream in the list: a field number calculated with the formula: 0
 a view to presenting these son
a view to presenting these son The RSS page display RSS web son is actually a view. This view will be sorted from the field position. We do not want to display the URL of the wire but its content. The second column in the view will therefore present a call to a javascript function that displays the contents of the wire is clear:
- first column (sort ascending): position
- 2nd column: "\u0026lt;div id = \\ "taglist" + @ Text (@ DocumentUniqueID) + "\\" class = \\ "rss \\"> \u0026lt;script type=\\"text/javascript\\"> loadRSS ('"+ URL +"', 'taglist " + @ Text (@ DocumentUniqueID) + "'," + entries +");\u0026lt;/ script> \u0026lt;/ div> "
mask to present the view
The mask should be named $ $ for ViewTemplate MaVueRSS where MaVueRSS is the name of the view created above. For simple reasons of simplification of presentation of the code I will define this mask with the option content type: HTML accessible from the second tab of the options mask.
Management drag & drop
As seen in the first section of this presentation, management drag and drop with Scriptaculous is really very simple.
\u0026lt;head>
\u0026lt;script src="scriptaculous/lib/prototype.js"> \u0026lt;/ script> \u0026lt;script
src="scriptaculous/src/scriptaculous.js"> \u0026lt;/ script> ;
\u0026lt;/ head>
\u0026lt;body>
\u0026lt;div id="NewOrder">
FOR INTEGRATED
\u0026lt;/ div> \u0026lt;script type="text/javascript">
Sortable.create ('NewOrder', {tag: 'div'});
\u0026lt;/ script>
\u0026lt;/ body>
Recovery RSS
Using prototype simplifies AJAX call to retrieve the RSS feed:
loadRSS function (url, fieldname, nbentrees)
{var = new Ajax.Request myAjax (
url
{method: 'get',
});}
Interpretation of Feed
The interpretive function of the RSS feed should be called when the file was recovered, either onComplete event. The function automatically receives as parameter the query result: OriginalRequest . A file
RSS is an XML file, like Google Maps . The advantage of not being able to exit the field is that one can master the syntax of this format and thus greatly simplify the code. An example of Javascript code to retrieve the information displayed is:
loadRSS function (url, fieldname, nbentrees)
{var = new Ajax.Request myAjax (
url
{method: 'get',
onComplete: function (OriginalRequest) {items =
originalRequest.responseXML;
if (parseInt (nbentrees) == 0) nbentrees = '5 ';
var items_count
= (parseInt (nbentrees) \u0026lt;items.getElementsByTagName (' item ' ). length)?
parseInt (nbentrees): items.getElementsByTagName ('item'). Length;
for (var i = 0; i \u0026lt;items_count; i + +) {
root_node items.getElementsByTagName = ('item') [i];
title
root_node.getElementsByTagName = ('title') [0]. firstChild.data;
root_node.getElementsByTagName link = ('link') [0]. firstChild.data;
publication =
root_node.getElementsByTagName ('pubDate') [0]. firstChild.data;
root_node.getElementsByTagName author = ('author') [0]. firstChild.data;
}}}
);}
Display result
To display the result in the \u0026lt;div> I use one of the most essential functions of the prototype to my taste: $ ('id ').
$ ('id') can simply retrieve the element with id 'id'. In the present case, 'id' is fieldname. To integrate HTML into the div I'll use innerHTML . The final code of the function is:
loadRSS function (url, fieldname, nbentrees)
{var
myAjax = New Ajax.Request (url
,
{method: 'get',
onComplete: function (original request) {
items = originalRequest.responseXML;
if (parseInt (nbentrees) == 0) nbentrees = '5 ';
was items_count
= (parseInt (nbentrees) \u0026lt;items.getElementsByTagName ('item'). length)?
parseInt (nbentrees): items.getElementsByTagName ('item'). length;
was feed = '\u0026lt;h1> ; '+
items.getElementsByTagName (' title ') [0]. firstChild.data +' \u0026lt;/ h1> ';
for (var i = 0; i \u0026lt;items_count; i + +) {
root_node = items.getElementsByTagName ('item') [i];
root_node.getElementsByTagName title = ('title') [0]. FirstChild.data;
root_node.getElementsByTagName link = ('link') [0]. FirstChild.data;
publication =
root_node.getElementsByTagName ('pubDate ') [0]. firstChild.data;
root_node.getElementsByTagName author = (' author ') [0]. firstChild.data;
feed + =' \u0026lt;h2> \u0026lt;a href = '+ link +' > '+ title +
' \u0026lt;/ a> \u0026lt;/ h2> \u0026lt;h3> '+ author +' '+
publication +' \u0026lt;/ h3> ';}
$ (fieldname). InnerHTML = feed;}
});}
By adding a few lines of CSS style you get the result shown on the demo database .
0 comments:
Post a Comment